DeepLab
An Overview about DeepLab...
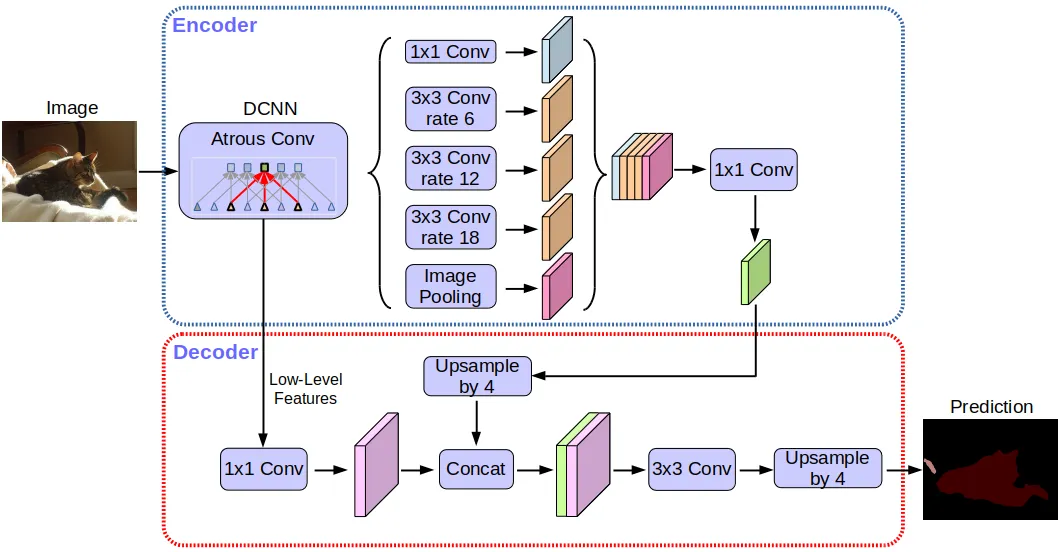
All of this post I rewrote from this post; the author has a very comprehensible explanation.
DeepLab Overview
DeepLab is a family of convolutional neural network (CNN) architectures designed for semantic segmentation in computer vision. These models are known for their ability to capture fine-grained details and perform semantic segmentation on high-resolution images. The DeepLab architecture has undergone several iterations, each with improvements to achieve better results in various computer vision tasks. Here’s an explanation of DeepLab, its methods, results, and architecture:
Methods
DeepLab models incorporate several key methods and components to achieve state-of-the-art results in semantic segmentation:
Dilated Convolutions (Atrous Convolutions):
DeepLab employs dilated convolutions, also known as atrous convolutions, which allow the network to capture multi-scale contextual information without down-sampling the spatial resolution of feature maps. This is crucial for preserving fine details while maintaining a large receptive field.Atrous Spatial Pyramid Pooling (ASPP):
DeepLabv3 and later versions use ASPP, which is a module that employs multiple parallel atrous convolutions with different rates. ASPP enables the network to capture contextual information at multiple scales, improving segmentation accuracy.Backbone Network:
DeepLab can be combined with various backbone networks, such as ResNet or MobileNet, which provide the initial feature representation. The choice of backbone network influences the overall performance and computational efficiency of the model.CrfRnn:
Some versions of DeepLab incorporate a CRF (Conditional Random Field) as a post-processing step to refine the segmentation results. This step helps smooth the boundaries and improve the quality of the output.
Results
DeepLab models have consistently achieved state-of-the-art results in various computer vision tasks, including semantic segmentation, instance segmentation, and object detection. These models are widely used in applications such as autonomous driving, satellite image analysis, medical image analysis, and more. Some specific results achieved by DeepLab models include:
- High accuracy in pixel-wise segmentation, particularly on large and high-resolution images.
- The ability to segment fine-grained details, such as small objects and object boundaries.
- Robust performance in challenging scenarios, like urban scenes and medical imaging.
- Competitive results in instance segmentation tasks when combined with Mask R-CNN.
Architecture
The architecture of DeepLab models can be summarized as follows:
Backbone Network:
The model starts with a backbone network (e.g., ResNet or MobileNet) that extracts feature maps from the input image.Atrous Convolutions:
The feature maps are processed through atrous convolutions with different rates to capture multi-scale context.Atrous Spatial Pyramid Pooling (ASPP):
ASPP is applied to the feature maps to capture context at multiple scales. It includes parallel atrous convolutions with different rates.Upsampling:
The final feature maps are upsampled to match the original image resolution.Final Segmentation:
The upsampled feature maps are used to generate the final pixel-wise segmentation map.CRF (optional):
In some versions, a CRF may be applied as a post-processing step to refine the segmentation results.
DeepLab is a flexible architecture that can be adapted for various tasks and applications by adjusting the backbone network and other components. It has played a crucial role in advancing the field of semantic segmentation and remains a top choice for researchers and practitioners in computer vision.
Magic in DeepLab
- Utilizes atrous convolution to enable kernels to capture a larger field of view, improving the ability to understand context.
- Implements ASPP (Atrous Spatial Pyramid Pooling) to apply atrous convolutions with multiple dilation rates, effectively capturing varying levels of context (e.g., when to focus on broader areas and when to zoom in :D).